
One of Anagolay strong points is the capability to generate code by combining Operations into a Workflow, given a manifest that is plain JSON.
This task is performed by the publish service through a template that, once fed with the Workflow manifest and all the required Operation information along with their Versions, produces some Rust code that is suitable to be called from WASM or natively and is preferably no-std (all Operations involved permitting this). This is important because it makes the Workflow very versatile, in fact:
- Rust is a widespread system language and if the Workflow is performant and supports no-std it can possibly be executed also on a Rust-based blockchain, like substrate.
- WASM is a standard assembly format that can run in the browser, under nodejs, and potentially be integrated with other environments as well.
In the following paragraphs, I will go through the different phases of implementation of the Workflow generation, outlining the difficulties I faced and the search for performance improvements. I believe my experience could be useful for many (or at least interesting for some).
How it all started
A few months ago I got my hands on a POC of some Operations written in Rust and compiled to WASM, the initial form of what would be automated code generation and execution, a.k.a a Workflow.
A test scenario for the performance was going to be producing a CID v1 out of some bytes, using the sequence of op_multihash and Blake3 encoder with op_cid.
The initial idea which we respected this far is that both Operations and Workflows should have the following characteristics:
- Have a native (Rust) and a WASM interface
- Be capable, where possible, of working in both std and no-std environment
- Have similar structure, from their manifest to their implementation (which, of course, may vary)
- Be capable of high throughput and asynchronous
- An exceptional category of Operations is represented by those that can get an indefinite number of inputs of any type and produce one output out of them (
FLOWCONTROLgroup)
Implementing all the above criteria appeared to be a real challenge, pushing the limit of what the Rust language allows, but let’s start from the beginning.
Crossing the WASM boundary
The first problem I focused on was sharing objects between the Javascript interpreter memory and the WASM memory. The thing is that once a WASM method returns, its memory is deallocated, so WASM cannot return references to locally created objects because such references would be invalid once Javascript tries to access them. It is, though, possible to maintain those references if they belong to a “registry” object which has a WASM-bound implementation instantiated in the scope of Javascript, like in the Rust WASM tutorial. On the other hand, a common approach is to deserialize the input of the WASM functions and serialize their output, since, aside from the cost of the procedure, the transfer across the boundary is very performant. So these were my considerations:
- Registry approach:
- PROS: no performance loss due to serialization since it’s possible to return references to WASM memory
- CONS: the Javascript code looks cumbersome since everything must pass through this registry. All Operations have a dependency on this central entry point, which complicates the compilation to WASM. This is what I thought it would look like to invoke an Operation:
let opOutput = Anagolay.runOperation('op_cid', inputs, config) - Serialization/Deserialization, the chosen approach:
- PROS: the js code is sleek and every Operation is completely independent of the others
let opOutput = op_cid(inputs, config)- CON: there was a huge overhead in method calls, dependent on the performance of the
serde-serializefeature ofwasm-bindgen, which serializes to JSON.
Introducing near-to-memory serialization
Having tested quickly [serde-wasm-bindgen](https://crates.io/crates/serde-wasm-bindgen) as well and not having obtained good enough results for bytes input (oh, I will come back on this…), I proceeded to evaluate the fastest (de)serializer I could find, one that almost copies and restores the content of the memory, which (among other choices) is [bincode](https://crates.io/crates/bincode).
Uint8Array can cross the WASM boundary with little overhead; therefore we required an Operation to produce an OperationOutput that provides two methods:
as_input()to be called whenever it must be given in input to another Operation since it will produce itself asUint8Array. This call is fast and occurs often, from one Operation to the other.decode()to be called to access the actual value in Javascript (a WASM-bound object or a primitive type). This call has a performance impact and it’s intended just for the final result.
This approach turned out to be one order of magnitude faster than serializing to JSON but introduced a lot of complications due to this OperationOutput dual representation.
It was necessary to have this definition as a trait, but traits don’t go well along with wasm-bindgen. However, through a derive macro, it’s possible to have the WASM-bound struct implement a trait (only from the Rust point of view):
pub fn impl_operation_return_trait(return_type: &Ident, struct_item: &ItemStruct) -> TokenStream {
let name = &struct_item.ident;
let gen = quote! {
#struct_item
// omitted downcast implementation
impl an_operation_support::operation::OperationOutput<#return_type> for #name {
fn as_input(&self) -> js_sys::Uint8Array {
<#name>::as_input(self)
}
fn decode(&self) -> #return_type {
<#name>::decode(self)
}
}
};
gen.into()
}
The macro implementation made sure that no compilation was possible without the required methods, and that they were implemented coherently:
#[operation_return_type(String)]
pub struct MyOperationOutput {
state: String
}
impl MyOperationOutput {
pub fn as_input(&self) -> js_sys::Uint8Array {
// omitted serialization code
}
pub fn decode(&self) -> String {
self.state.to_string()
}
}
Complexity was growing but it was an acceptable tradeoff to have such good performances: using this approach, we could grind 16KB of data and get their CID in an astonishing 0.27ms from the WASM interface.
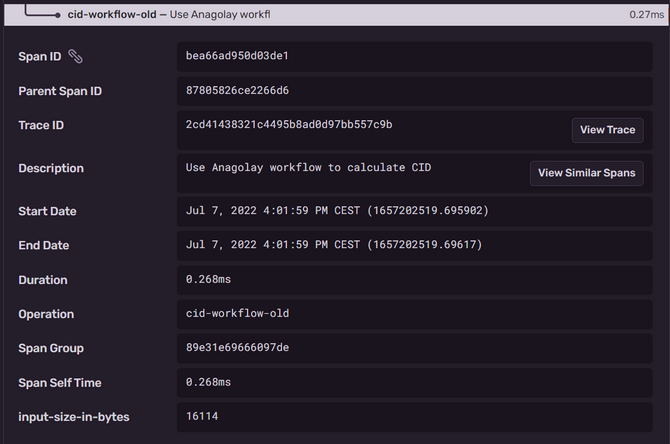
A side problem: manifest generation
Since one of the objectives is to have all Operations structured similarly, their manifest is generated directly from the code, through a derive macro applied to the execute() function. A problem arose since such function was returning a dynamic implementation of trait OperationOutput, generic-typed with the real return type of the Operation.
#[describe([
groups = [
"SYS",
],
config = []
])]
pub async fn execute(
state: &String,
_: BTreeMap<String, String>,
) -> Result<Box<dyn an_operation_support::operation::OperationOutput<String>>, String> {
Ok(Box::new(MyOperationOutput { state: state.to_string() }))
}
At that time, in the WASM-bound execute function, this dynamic trait needed to be downcasted to the actual MyOperationOutput implementation that was WASM-bound and returned to Javascript:
#[wasm_bindgen(js_name=execute)]
pub async fn wasm_execute(
operation_inputs: Vec<Uint8Array>,
config: Map,
) -> Result<MyOperationOutput, JsValue> {
// omitted code to deserialize input and config map
execute(&deserialized_input, deserialized_config)
.await
.map(|operation_output| MyOperationOutput::downcast(operation_output))
.map_err(|error| JsValue::from_str(&error.to_string()))
}
This magic can be done with some unsafe code from the OperationOutput trait implementation (previously omitted in the impl_operation_return_trait() snippet):
impl #name {
pub fn downcast(trait_impl: Box<dyn an_operation_support::operation::OperationOutput<#return_type>>) -> #name {
let raw = Box::into_raw(trait_impl) as *mut #name;
unsafe { raw.read() }
}
}
Hitting the wall with flow-control Operations
Even with all the boilerplate code and the explicit type declarations, all was working well as long as it was possible to know the cardinality and the type of the inputs and output of the Operation. This is not the case when we need to provide an Operation that collects several results into one array, or, even more naively, outputs the identity. These are possible behaviors for an Operation of the FLOWCONTROL group, called op_collect, which provides no input or output in its manifest (as it’s not known in advance) but has them specified in the Workflow manifest when op_collect is used in conjunction with other operations.
Whenever I looked at the problem, I found it impossible to declare or implement the OperationOutput trait for the output of op_collect, and difficult to get around Rust's strict type checking to provide a variable cardinality of inputs, having unknown types.
In the end, the Rust side was the easiest to implement, since in this category of Operations the execute() function is substituted by an execute!() macro and the Operation manifest is generated by a derive macro out of the latter. But implementing the WASM, required completely reconsidering the direction I had taken.
OperationOutput dual input/decode nature became a problem since there is no information about its decoded type in the WASM-bound execute() function of op_collect. Therefore I had to get rid of the structure completely, unwrapping the type it was wrapping and having all values passed to Javascript as serialization of themselves, and not as bytes.
This way, FLOWCONTROL Operation WASM implementation can blindly deal with JsValue input and produce a JsValue output, ignoring which objects it is actually manipulating: the only way to do so was reverting to serde_wasm_bindgen. The code was greatly simplified and I was much more satisfied with the code readability and architecture:
#[describe([
groups = [
"SYS",
],
config = []
])]
pub async fn execute(
state: &String,
_: BTreeMap<String, String>,
) -> Result<String, String> {
Ok(state.to_string())
}
#[wasm_bindgen(js_name=execute)]
pub async fn wasm_execute(
operation_inputs: Vec<JsValue>,
config: Map
) -> Result<JsValue, JsValue> {
// omitted code to deserialize input and config map
let output = execute(&input, config).await?;
serde_wasm_bindgen::to_value(&output)?
}
However, as had happened before, this approach (above in the graphs) proved to be much less performant than bincode implementation (below in the graphs). The loss was not negligible as the size of the input increased:

64KB of data
800KB of data
This had actually to do with the way an array of bytes is treated by the serializer. Differently from bincode decoding, **serde-wasm-bindgen requires ownership of the value it’s deserializing**, which in turn means that the whole array was cloned just to be transformed from a JsValue into a Vec<u8> (aliased Bytes). But this can be done in a much more efficient way, retaining only the reference for the cast of JsValue to UInt8Array:
pub fn from_bytes(operation_input: &JsValue) -> Result<Bytes, JsValue> {
let cast: Option<&Uint8Array> = operation_input.dyn_ref();
match cast {
Some(array) => Ok(array.to_vec()),
None => Err(JsValue::from_str(
"Expected a JsValue that could be casted to UInt8Array",
)),
}
}
The Workflow template
Particular attention was given to writing the handlebars template that generates the Workflow; indeed, it proved to be beneficial to have a slightly more complicated template that is capable of recognizing several different cases rather than a simpler one which is more readable but produces less performant code.
The fact of avoiding crossing the WASM boundary by calling in sequence Operations that belong to the same Segment, along with the memoisation of Segment execution results to be used afterward, is much more performant and user-friendly than calling each operation manually from Javascript.
Both the WASM-bound structure and the asynchronous trait implementation expose only two methods: the constructor and the next(), which will advance up to the point that some external input is required or the Workflow is terminated.
The generated code is meticulously tuned for performance, from the explicit Bytes deserialization described before, to the fact that only the last segment of the WASM-bound Workflow will spend time serializing the Workflow output; all these practices are reasoned by the considerations made previously.
Wherever is possible, and most extensively as it can go, instead of calling clone() or to_owned() on values, they are wrapped into **Rc to reuse references**. The native code pushes it even further by returning a reference also in the Workflow output, and it’s up to the caller to decide whether to take ownership or not.
All these final optimizations achieved in this latest Workflow (below in the graphs) allowed us to perform even a little better than the original bincode Workflow (above in the graphs):
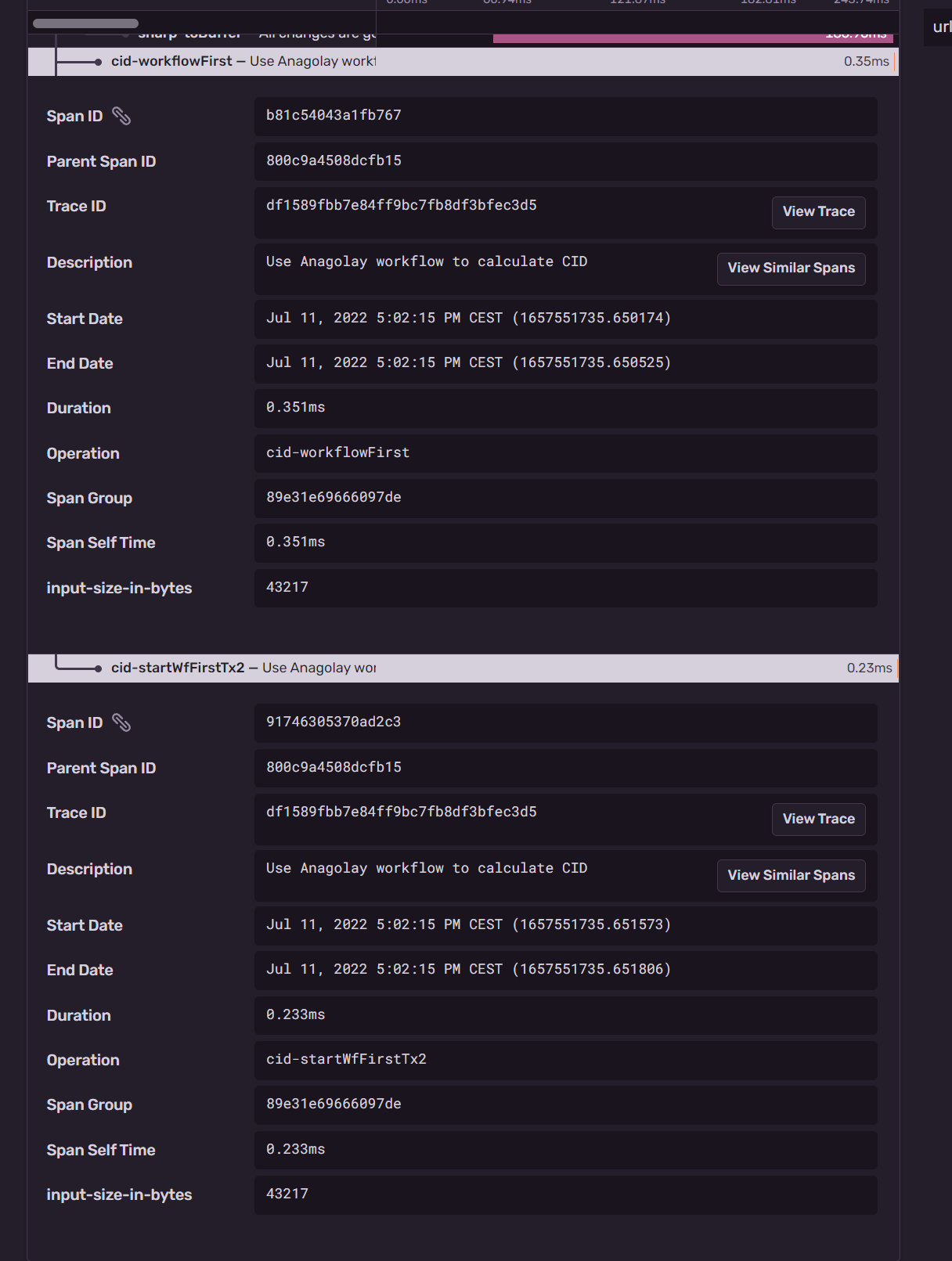
Conclusion
To sum up, this search for performance will make the difference when calling the WASM interface while dealing with an even higher amount of input data nearly real-time. Moreover, the possibility to call the same code from the native Rust interface as well greatly increases the versatility of the code written in the form of an Anagolay Workflow. If you want to learn more about this implementation and Anagolay Workflows - join our Discord server or follow our updates on Twitter.
14.07.2022